
علی روحانی؛ برنامه نویس وب
هر چه درباره برنامه نویسی و ماشین و گیمینگ بخونم و برام جالب باشه، اینجام می نویسمشتوسط ۱ نفر دنبال می شود

اپل مدل زبان جدیدی معرفی کرده که متنهای بلند را با سرعتی 128 برابر سریعتر از مدلهای مشابه تولید میکند.
مدل زبانی جدید اپل با بهرهگیری از معماری پیشرفته قادر است متنهای بلند و پیچیده را با سرعتی فوقالعاده و دقت بالا تولید کند. براساس گزارشها، تیم تحقیقاتی اپل یک مدل مبتنی بر Diffusion ارائه کرده است که میتواند متنها را تا 128 برابر سریعتر از مدلهای مشابه ایجاد کند.
مدلهای زبانی بزرگ مانند ChatGPT از نوع Autoregressive هستند؛ این مدلها متن را بهصورت توکن به توکن و پشت سر هم تولید میکنند و هر توکن را با در نظر گرفتن ورودی کاربر و تمام توکنهای پیشین میسازند.
در مقابل، مدلهای Diffusion چند توکن را همزمان تولید کرده و در چند مرحله اصلاح میکنند تا پاسخ نهایی شکل بگیرد. یکی از انواع پیشرفته این مدلها، Flow-matching است که مراحل اصلاح چندگانه را کنار میگذارد و تلاش میکند نتیجه نهایی را در یک مرحله بهدست آورد.
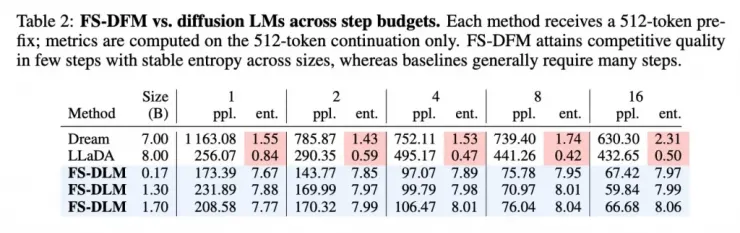
مطالعه جدید اپل با عنوان «FS-DFM: Fast and Accurate Long Text Generation with Few-Step Diffusion Language Models» یک مدل جدید موسوم به Few-Step Discrete Flow-Matching (FS-DFM) معرفی میکند. این مدل میتواند متنهای بلند را تنها با هشت مرحله اصلاح با سرعتی زیادی تولید کند، درحالیکه مدلهای Diffusion معمولی بیش از هزار مرحله نیاز داشتند تا کیفیت مشابه ارائه دهند.
برای رسیدن به این سرعت، پژوهشگران از سه مرحله استفاده کردهاند: ابتدا مدل آموزش میبیند که چندین مرحله اصلاح متن را مدیریت کند، سپس یک مدل «معلم» برای انجام بهروزرسانیهای دقیق و بزرگتر در هر مرحله به کار گرفته میشود و در نهایت نحوه اجرای هر مرحله بهینه میشود تا مدل بتواند با طی مراحل کمتر و ثبات بیشتر به نتیجه برسد.

در مقایسه با مدلهای بزرگ مشابه، FS-DFM در معیارهای «آنتروپی» و «سردرگمی» عملکرد قابل توجهی داشته است. سردرگمی کیفیت متن را اندازه میگیرد؛ هرچه پایینتر باشد، متن طبیعیتر و دقیقتر است. آنتروپی میزان اطمینان مدل در انتخاب هر کلمه را نشان میدهد؛ مقدار پایین متن را تکراری یا قابل پیشبینی میکند و مقدار زیاد باعث میشود متن نامنسجم یا تصادفی شود.
مدل FS-DFM با پارامترهای 1.7، 1.3 و 0.17 میلیارد، در مقایسه با مدلهای Dream و LLaDA با 7 و 8 میلیارد پارامتر، در معیار سردرگمی عددی پایینتر و در آنتروپی نتیجهای پایدارتر بهدست آورد.
باتوجهبه عملکرد عالی و کمبود مدلهای مشابه، پژوهشگران اعلام کردهاند که قصد دارند کد و چکپوینتهای مدل را منتشر کنند تا امکان بازتولید و تحقیقات بیشتر فراهم شود. مطالعه کامل مقاله در arXiv شامل نمونههای عملکردی و نمودارهایی است که مراحل اصلاح هر توکن و نحوه تغییرات آن را نشان میدهد.




پاسخ ها