

متا از محتوای عمومی فیسبوک و اینستاگرام کاربران اتحادیه اروپا برای آموزش مدلهای هوش مصنوعی خود استفاده نمیکند.
متا تأیید کرده است که برنامههای خود را برای شروع آموزش سیستمهای هوش مصنوعی با استفاده از دادههای کاربرانش در اتحادیه اروپا و بریتانیا متوقف میکند. مدتی پیش این شرکت اعلام کرد که برای آموزش مدلهای هوش مصنوعی خود از دادههای کاربران اینستاگرام و فیسبوک بهره میبرد که پس از آن نیز با شکایت اتحادیه اروپا مواجه شد.
براساس گزارش رویترز، متا گفته است که کمیسیون حفاظت از دادههای ایرلند (DPC) از آن خواسته است آموزش مدلهای زبانی بزرگ (LLM) خود با استفاده از محتوای عمومی بهاشتراک گذاشتهشده توسط کاربران فیسبوک و اینستاگرام را متوقف کند.
متا نیز گفته است بدون استفاده از اطلاعات محلی کاربران اروپایی، این شرکت فقط میتواند تجربه درجه دومی را به این کاربران ارائه دهد. این شرکت میگوید که باید این کار را انجام دهد تا زبانها، جغرافیا و مشخصات فرهنگی مختلف مردم اروپا را در هوش مصنوعی خود منعکس کند. بهاینترتیب متا ممکن است هوش مصنوعی خود را در اروپا عرضه نکند و یا با تأخیر آن را در دسترس این کاربران قرار دهد.

متا از چند هفته گذشته کاربران خود را درباره تغییر در خطمشی حریم خصوصی خود مطلع کرده است؛ در این تغییرات به متا این حق داده میشود تا از محتوای عمومی کاربران فیسبوک و اینستاگرام برای آموزش هوش مصنوعی خود استفاده کند. این تغییرات قرار بود در 26 ژوئن (6 تیر) اعمال شود. اما این شرکت با شکایت اتحادیه اروپا مواجه شد. در این شکایت ذکرشده که برای چنین کاری، ابتدا باید از کاربران اجازه گرفته شود تا درصورت عدم تمایل بتوانند انصراف دهند.
متا نیز گفته است که بیش از 2 میلیارد نوتیفیکیشن برای کاربران ارسال کرده است تا آنها را از تغییرات آتی آگاه کند، اما برخلاف سایر پیامهای عمومی مهم که در بالای فید کاربران قرار میگیرند، این نوتیفیکشن در کنار دیگر نوتیفیکشنها ظاهر میشود و ممکن است بسیاری از کاربران آن را نادیده بگیرند.
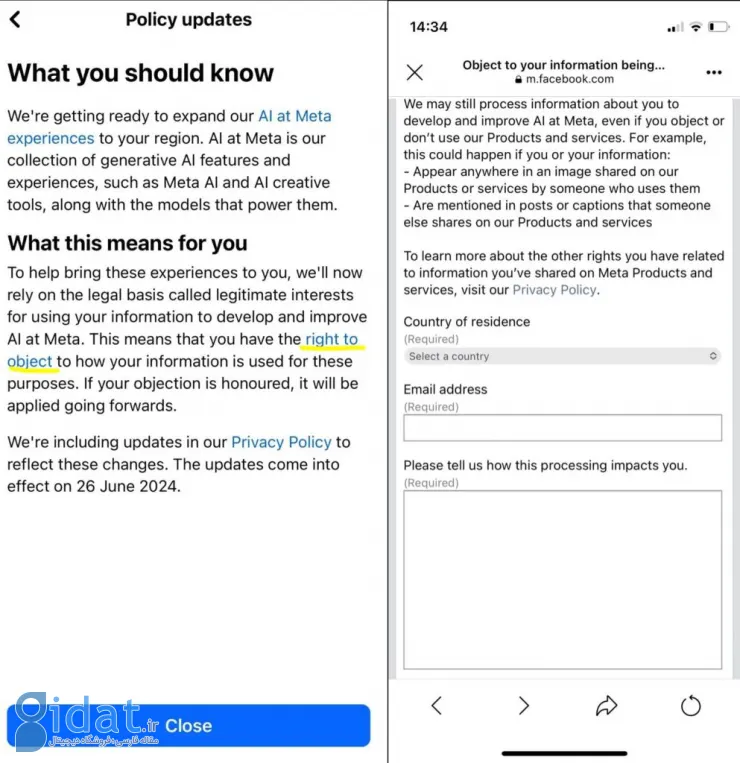
علاوهبراین، کاربران مستقیماً و بهسادگی قادر به «انصراف» از استفاده از دادههایشان نیستند. درعوض، آنها باید یک فرم اعتراض را تکمیل کنند که در آن استدلالهای خود را برای اینکه چرا نمیخواهند دادههایشان پردازش شود، ارائه دهند.
!["هوش مصنوعی مادربزرگ" برای خنثی کردن کلاهبرداران تلفنی معرفی شد [Watch]](https://idat.ir/upload/attach/15150/ai_granny_910x600_0.webp)


پاسخ ها