

توسعه هوش مصنوعی پیشرفته به دادههای آموزشی جدید و باکیفیتی نیاز دارد، اما این دادهها محدود هستند.
چند روز قبل اینفورمیشن در گزارشی گفت که کارمندان OpenAI مدل جدیدی به نام رمز Orion را آزمایش کردهاند که هرچند عملکرد آن از مدلهای فعلی فراتر میرود، اما نسبت به جهش از GPT-3 به GPT-4 پیشرفت کمتری دارد. اکنون کارشناسان این مسئله را مطرح میکنند که شاید دیگر توسعه مدلهای هوش مصنوعی پیشرفتهتر به یک قله رسیده و حالا روبهروی ما دشت همواری است، یعنی چه بسا تا چند سال آینده، دیگر شاهد جهشهای خارقالعاده و قلههای بلندتری در این زمینه نباشیم.
به گفته محققان OpenAI که نام آنها فاش نشده، مدل جدید Orion در انجام برخی کارها بهتر از مدل قبلی خود نخواهد بود. از سویی گفتههای جدید «ایلیا ساتسکیور» (Ilya Sutskever)، یکی از بنیانگذاران OpenAI که اوایل سال جاری میلادی این شرکت را ترک کرد، به این نگرانی دامن میزند که مدلهای زبانی بزرگ (LLM) درحالحاضر به یک سطحی رسیدهاند که دیگر نمیتوان با روشهای آموزش سنتی آنها را پیشرفتهتر کرد.

ساتسکیور به رویترز گفت که دهه 2010 عصر مقیاسبندی بود؛ عصری که با افزایش منابع محاسباتی و دادههای آموزشی بیشتر شاهد پیشرفتهای چشمگیری در مدلهای بعدی بودیم. اما اکنون قلههای این عصر فتح شدهاند و دوباره باید به دنبال چیزهای جدیدی برای کشفکردن باشیم.
به گفته متخصصان، مشکل بزرگ آموزش مدلهای هوش مصنوعی فقدان دادههای متنی جدید و باکیفیت برای آموزش LLMهای آتی است. اگر دادههای آموزشی یک مدل هوش مصنوعی را به میوههای یک درخت تشبیه کنیم، تاکنون تمام میوههای شاخههای پایینی چیده شدهاند؛ مدلهای هوش مصنوعی فعلی با آرشیو مطالب موجود اینترنت، اعم از سایتهای خبری و کتابها آموزش دیدهاند، اکنون باید به سمت میوههایی برویم که از شاخههای بالاتر درخت آویزان هستند.
محققان سعی کردند این مشکل را در مقالهای کمیسازی کنند و میزان مجموعه دادههای آموزشی برای LLM را اندازهگیری کنند و موجودی متنهای عمومی تولیدشده توسط انسان را تخمین بزنند. محققان میگویند که «مدلهای زبانی بهطور کامل از ذخیره متنهای عمومی تولیدشده توسط انسان بین سالهای 2026 تا 2032 استفاده خواهند کرد.»
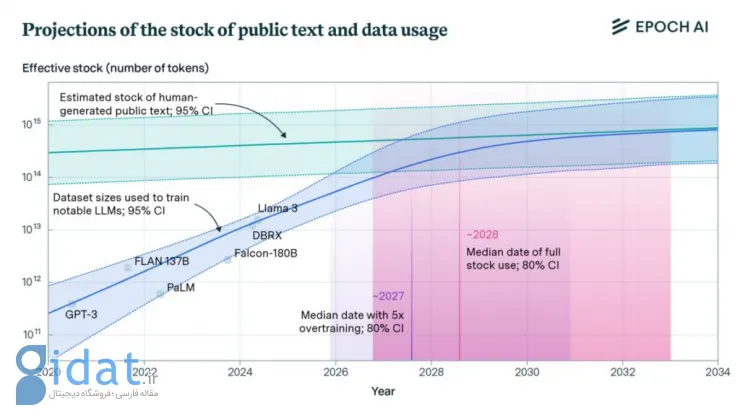
OpenAI و سایر شرکتهای پیشرو از اکنون شروع به آموزش مدلهای خود با دادههای مصنوعی (ایجادشده توسط مدلهای دیگر) کردهاند تا از این بنبست که به سرعت درحال نزدیکشدن است، عبور کنند. بااینحال ممکن است دادههای مصنوعی پس از چند دوره آموزش منجر به «فروپاشی مدل» شود.
البته شرکتهای بزرگ فناوری روشهای آموزشی دیگری را نیز امتحان کردهاند، برای مثال یکی از این روشها تخصصیکردن فرایند آموزش مدل است. مایکروسافت با مدلهای زبانی کوچک که روی انواع خاصی از وظایف و مسانل تمرکز میکنند موفقیتهایی را در این زمینه کسب کرده است. برخلاف LLMهای عمومی که امروزه به آنها عادت کردهایم، میتوانیم در آینده هوشهای مصنوعی را ببینیم که بر تخصصهای محدودتری متمرکز هستند، دقیقاً مانند دانشجویان دکترا که شاید دانش عمومی زیادی نداشته باشند، اما در یک رشته خاص میتوانند مسیرهای جدیدی را خلق کنند.





پاسخ ها