اگر از علاقهمندان به دنیای فناوری باشید، مسلما عبارت «یادگیری ماشینی» (ML) را شنیدهاید. یادگیری ماشینی در سالهای اخیر مورد توجه بسیاری قرار گرفته، اما باید بدانید این مفهوم از چندین دهه پیش وجود داشته. در این مطلب میخواهیم شما را به صورت کامل با یادگیری ماشینی و انوع آن آشنا کنیم و همچنین نگاهی به تفاوتهای آن با هوش مصنوعی و یادگیری عمیق داشته باشیم.
طراحی سیستمهای یادگیری ماشینی مبتنی بر مدل مغز انسان است که در سال ۱۹۴۹ در کتابی به نام «سازمان رفتار» اثر یک روانشناس و عصبپژوه به نام «دونالد هب» توصیف شده. طبق نوشته هب در این کتاب، زمانی که سلولها درون مغز در یک الگوی تکراری کار میکنند، عملکردهای سیناپسی شکل میگیرند یا در صورت وجود، بزرگتر میشوند.
مهندسان از همین اصل در نودها در شبکه عصبی دیجیتال استفاده میکنند. نودها روابطی را شکل میدهند که اگر بطور همزمان فعال شوند، قویتر میشوند و اگر به صورت جداگانه فعال شوند، ضعیف میشود. یادگیری تقویتی یکی از شکلهای یادگیری ماشینی مبتنی بر این مفهوم است، اما فعلا با آن کاری نداریم و در بخشهای بعدی آن را معرفی میکنیم.
یکی از برنامهنویسها IBM و پیشگامان هوش مصنوعی (AI) به نام «آرتور ساموئل» در سال ۱۹۵۲ اصطلاح یادگیری ماشینی را ابداع کرد. ساموئل در آن زمان یک برنامه برای بازی «چکرز» توسعه داد که توانایی یادگیری داشت و هرچه بیشتر بازی میکرد، عملکرد آن بهتر میشد.
ساموئل از تکنیکی به نام «هرس آلفا بتا» استفاده کرد که بر اساس موقعیت مهرهها و شانس پیروزی هر طرف به آنها امتیاز میداد. این مدل به الگوریتم «مینیماکس» تکامل پیدا کرده که هنوز به مهندسان آموزش داده میشود.

قدمت یادگیری ماشینی به چندین دهه پیش برمیگردد
در طی دهههای گذشته، پیشگامان دیگری از راه رسیدند و موارد بیشتری را به مدلهای هب و ساموئل اضافه کردند و کاربردهای آنها را افزایش دادند. برای مثال در سال ۱۹۵۷ فردی به نام «فرانک روزنبلات» پرسپترون «مارک ۱» را ساخت که یکی از اولین ماشینهای تشخیص چهره و اولین ماشین عصبی موفق بود.
«مارچلو پلیلو» یک دهه بعد یعنی در سال ۱۹۶۷ «قانون نزدیکترین همسایه» را برای تشخیص الگو توسعه داد. این الگوریتم پدربزرگ برنامههای نقشهبرداری GPS امروزی است. افراد دیگری در دهه ۶۰ و ۷۰ میلادی در این زمینه فعالیت داشتند و شبکههای عصبی مختلفی را توسعه دادند.
تمام این پژوهشها در گذشته سنگبنای تحقیقات امروزی هستند. بسیاری از کاربردهای آنها مانند تشخیص چهره و گفتار، تحلیل داده، پردازش زبان طبیعی و حتی هشدارهای فیشینگ در ایمیلهای ما مبتنی بر کار این افراد در گذشته هستند. امروزه اتوماسیون تقریبا در تمام بخشهای صنعتی وجود دارد و کاربرد یادگیری ماشینی را به اوج رساندهاند، اما همچنان کار در این زمینه ادامه دارد.
«آکادمیا» به یک تعریف مشخص برای یادگیری ماشینی بسنده نکرده. کاربرد یادگیری ماشینی بسیار گسترده است و نمیتوان آن را در یک جمله خلاصه کرد، هرچند تلاشهایی در این زمینه صورت گرفته. MIT برای آن نوشته:
«الگوریتمهای یادگیری ماشینی از آمارها برای یافتن الگوها در حجم بالایی از داده شامل اعداد، کلمات، کلیکها و هر چیزی که در اختیار دارید، استفاده میکند. اگر این اطلاعات به صورت دیجیتالی ذحیره شوند، میتوان آنها را در اختیار یک الگوریتم یادگیری ماشینی قرار داد.»
توصیف استنفورد برای یادگیری ماشینی به شرح زیر است:
«یادگیری ماشینی علمی است که طی آن کامپیوترها بدون اینکه بطور واضح و صریح برنامهریزی شده باشند، میتوانند عمل کنند.»
در نهایت دانشگاه «کارنگی ملون» گفته:
«یادگیری ماشینی به دنبال پاسخی برای این سوال است: چگونه میتوانیم سیستمهای کامپیوتری بسازیم که بطور خودکار با استفاده از تجربه بهبود پیدا کند و قوانین اساسی حاکم برای تمام فرایندهای یادگیری ماشینی کدامند؟»
اگر تمام جملات بالا را ترکیب و خلاصه کنیم، به این توصیف میرسیم: یادگیری ماشینی شامل آموزش یک کامپیوتر با تعداد بالایی مثال برای تصمیمگیری منطقی مستقل مبتنی بر حجم محدودی از دادهها به عنوان ورودی و بهبود این فرایند با استفاده از آن است.
در زمینه یادگیری ماشینی با مفاهیم دیگری مانند هوش مصنوعی و یادگیری عمیق (DL) هم مواجه میشویم. در حالی که این زمینهها به یکدیگر مرتبط هستند، اما با هم فرق میکنند. با اطلاع از ارتباط میان این فناوریها به کلید اصلی درک دقیق یادگیری ماشینی دست پیدا میکنیم.
هوش مصنوعی، یادگیری ماشینی و یادگیری عمیق سه دسته از علوم رایانه هستند که درون یکدیگر قرار گرفتهاند. یادگیری ماشینی زیرمجموعه هوشمند مصنوعی و یادگیری عمیق زیرمجموعه یادگیری ماشینی است. برای درک بهتر تصویر زیر را ببینید:
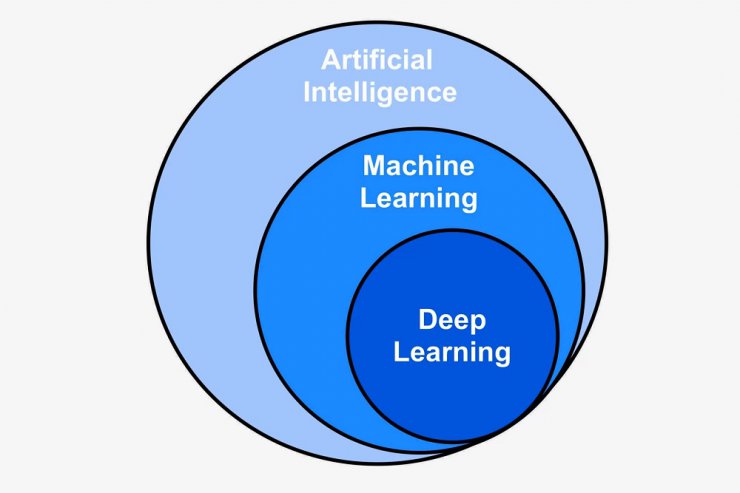
یادگیری ماشینی و یادگیری عمیق زیرمجموعه هوش مصنوعی هستند
هوش مصنوعی عمومی مجموعهای از دستورالعملها است که به کامپیوتر میگوید چگونه عمل کند یا رفتارهای مشابه با انسان را نشان دهد. نحوه واکنش نشان دادن آن به ورودیها کدنویسی سخت شده، برای مثال اگر چنین اتفاقی افتاد، این کار را انجام دهد. قانون کلی این است که اگر به هوش مصنوعی بطور واضح گفته شود که باید چه تصمیماتی بگیرد، این برنامه خارج از حوزه یادگیری ماشینی قرار میگیرد.
یادگیری ماشینی زیرمجموعهای از هوش مصنوعی است که میتواند بطور مستقل عمل کند. برخلاف هوش مصنوعی عمومی، نیازی نیست به یک الگوریتم ML نحوه تفسیر اطلاعات گفته شود. سادهترین شبکههای عصبی مصنوعی (ANN) از یک لایه از الگوریتمهای یادگیری ماشینی تشکیل شدهاند.
ANN مانند یک کودک نیاز به آموزش دارد و باید اینکار را با مجموعه دادههای طبقهبندی شده یا ورودی انجام داد. به بیان دیگر در هنگام معرفی داده، باید به ANN گفته شود که برای مثال در حال دریافت عکس یک گربه یا سگ است. با این کار پس از مدتی، ANN میتواند وظیفه خود را بدون دستورالعملهای صریح انجام دهد و خروجی یا نتایج را در اختیار ما قرار دهد.
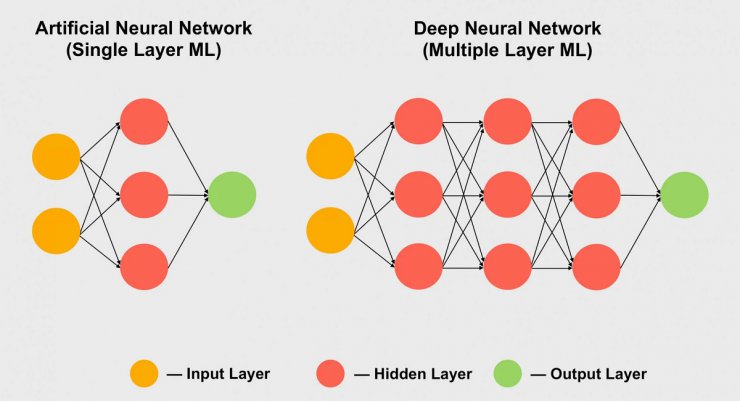
در نهایت یادگیری عمیق زیرمجموعه AI و ML است که از چندین لایه الگوریتمهای ML تشکیل شده. اغلب به یادگیری عمیق، شبکههای یادگیری عمیق یا DNN گفته میشود. ورودی از میان این لایهها عبور میکند و هرکدام از آنها یک صفت یا برچسب را به آن اضافه میکند. بنابراین یادگیری عمیق برای تفسیر اطلاعات نیازی به دادههای از پیش طبقهبندی شده ندارد.
در ادامه تفاوتها میان ML و DL و یادگیری شبکههای عصبی را بررسی میکنیم.
فرقی نمیکند به سراغ یادگیری ماشینی تک لایه یا شبکههای عصبی عمیق برویم چرا که هردوی آنها به آموزش نیاز دارند. در حالی که برخی برنامههای ML ساده میتوانند با حجم کمی از دادههای نمونه آموزش ببینند، بسیاری از آنها برای عملکرد دقیق به حجم بالایی داده نیاز دارند.
بدون توجه به نیازهای اولیه سیستم ML تحت آموزش، هرچه نمونههای بیشتری در اختیار آن قرار بگیرد، عملکردش بهتر میشود. DL معمولا به ورودی بیشتری در مقایسه با ML تک لایه نیاز دارد چرا که نحوه طبقهبندی اطلاعات را به آن نمیگوییم. استفاده از مجموعه دادههای حاوی میلیونها یا صدها میلیون مثال برای آموزش سیستمها امر غیرمعمولی نیست و تقریبا رایج است.
نحوه استفاده برنامههای ML از این حجم بالای دادهها به نوع یادگیری بستگی دارد. در حال حاضر سه مدل یادگیری شامل یادگیری نظارت شده، یادگیری بدون نظارت و یادگیری تقویتی داریم که در ادامه نگاهی به تمام آنها خواهیم داشت.
برخلاف اسم این نوع، اپراتورها نباید در هنگام کار آنها را تماشا کرده و خطاهای آنها را تنظیم کنند. در حقیقت یادگیری نظارت شده به معنای آن است که دادههای ورودی باید برچسبگذاری یا طبقهبندی شوند تا الگوریتمها وظایف خود را انجام دهند. سیستم باید از اطلاعات ورودی اطلاع داشته باشد تا بفهمد با آنها چه کار کند.
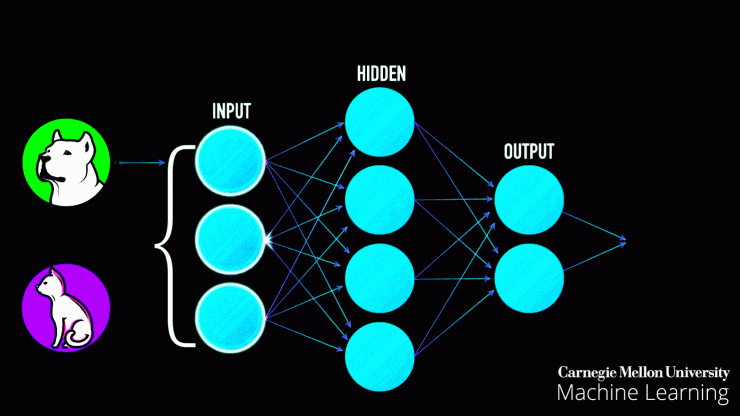
یادگیری نظارت شده به دادههای دستهبندی شده نیاز دارد
یادگیری نظارت شده یکی از رایجترین روشهای آموزش ML است و در بسیاری از برنامهها مورد استفاده قرار میگیرد. برای مثال بسیاری از سرویسها مانند پلی استیشن نتورک، نتفلیکس، اسپاتیفای و سایر سرویسهایی که به صورت خودکار فهرستی از اولویتهای کاربران ایجاد میکنند، از این روش بهره میبرند.
هربار که کاربر یک بازی میخرد، ویدیویی تماشا میکند یا به آهنگی گوش میدهد، الگوریتمهای ML آن را ثبت کرده و دادهها را تحلیل میکنند و به آنها برچسب میزنند. در نهایت این الگوریتمها به دنبال محتوای مشابه میگردند. با استفاده بیشتر از این سرویسها، الگوریتمها بهتر یاد میگیرند و بهتر میتوانند علایق کاربر را پیشبینی کنند.
یادگیری بدون نظارت نیازی به برچسبگذاری ندارد. در این نوع سیستم به دنبال الگوها میگردد و خودش دستهبندیها را ایجاد میکند. برای مثال اگر ورودی عکس یک سگ باشد، سیستم نمیتواند آن را به عنوان تصویر سگ دستهبندی کند چرا که دادهای برای اطلاع این موضوع به آن داده نشده. بجای اینکار، سیستم موارد دیگری مانند اشکال و رنگها را بررسی میکند و یک طبقهبندی اولیه و ناقص انجام میدهد. اگر اطلاعات بیشتری در اختیارش قرار بگیرد، میتواند پروفایل مربوط به سگها را اصلاح کند و همچنین تگهای بیشتری برای آنها تولید کند تا از سایر اجسام یا حیوانات قابل تشخیص باشند.
سیستم ML تک لایهای در هنگام کار با دادههای بدون برچسب یا دستهبندی عملکرد مناسبی از خود نشان نمیدهند. یکی از دلایل این موضوع، نیاز به شبکههای یادگیری عمیق برای درک اطلاعات است. شبکههای چندلایه برای این نوع دادهها مناسبتر هستند چرا که هر لایه پیش از انتقال دادهها همراه با نتایج به لایه دیگر، عملکرد خاصی روی آنها انجام میدهد. از آنجایی که شبکههای عصبی مصنوعی نسبت به شبکههای یادگیری عمیق مرسومتر هستند، یادگیری بدون نظارت رواج چندانی ندارد.
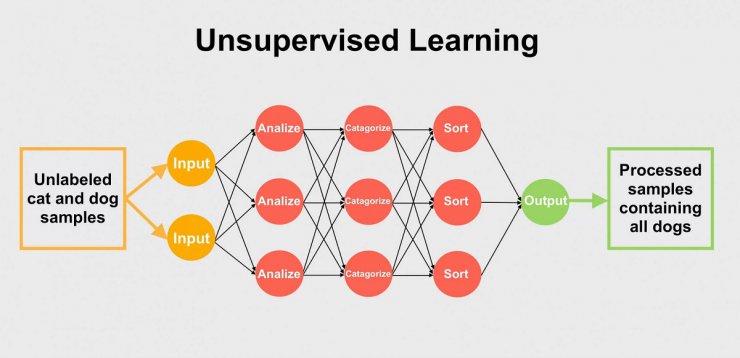
یادگیری بدون نظارت رواج کمتری نسبت به یادگیری نظارت شده دارد
با این وجود چندین مثال شناخته شده از سیستمهای ML وجود دارد که از یادگیری بدون نظارت استفاده میکنند. برای مثال «گوگل لنز» از این روش یادگیری برای تشخیص اجسام از تصاویر ایستا و زنده استفاده میکند. یکی دیگر از مثالها میتواند الگوریتمهای مورد استفاده توسط شرکت امنیتی «Darktrace» برای تشخیص نشتهای امنیتی داخلی باشد. سیستمهای ML این کمپانی از یادگیری بدون نظارت به گونهای استفاده میکند که بیشباهت به سیستم ایمنی بدن نیست.
سومین روش یادگیری هم با دادههای بدون برچسب سروکار دارد. در همین راستا از یادگیری تقویتی تنها در یادگیری عمیق استفاده میشود. سیستمهای بدون نظارت و تقویتی دادهها را با اهداف از پیش تعیین شده خاصی اداره میکنند. نحوه رسیدن آنها به اهداف جایی است که این الگوریتمها با هم تفاوت پیدا میکنند.
برخلاف یادگیری بدون نظارت که برای رسیدن به هدف نهایی درون پارامترهای مشخصی کار میکند، یادگیری تقویتی با استفاده از یک سیستم امتیازدهی به خروجی موردنظر خود نزدیک میشود.
این الگوریتمها راههای مختلفی را برای دستیابی به اهداف خود امتحان میکنند و با توجه به میزان موفقیت روش، به خود جایزه میدهند. یادگیری عمیق در آموزش هوش مصنوعی برای نحوه برنده شدن در بازیهایی مانند Go، شطرنج و حتی «پک-من» کارایی دارد.
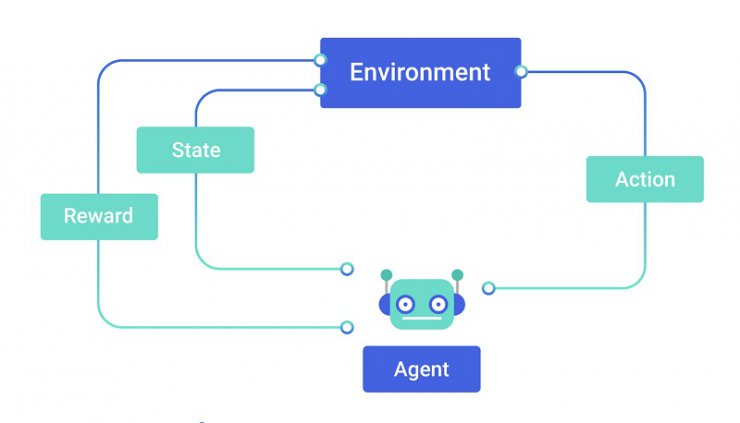
یادگیری تقویتی در سالهای اخیر مورد توجه زیادی قرار گرفته است
یادگیری تقویتی جدیدترین نوع آموزش سیستمهای یادگیری ماشینی است و در سالهای اخیر پژوهشهای زیادی درباره آن انجام شده. همانطور که بالاتر گفتیم، بازی چکرز ساموئل در سال ۱۹۵۲ یک نمونه اولیه از یادگیری ماشینی تقویتی بود. حالا برنامه یادگیری عمیق «آلفاگو» گوگل یا ربات Dota 2 به نام «OpenAI Five» میتوانند بازیکنان حرفهای را شکست دهند.
در حالی که چندین دهه از ابداع یادگیری ماشینی میگذرد، در سالهای اخیر به صورت عمده در دنیای فناوری از آن استفاده میشود. شما به صورت روزانه و منظم از دستگاهها یا اپهای مبتنی بر الگوریتمهای ML استفاده میکنید. یکی از این دستگاهها، گوشیهای هوشمند هستند که به اپهای مختلفی مانند دستیارهای صوتی، نقشهها و ردیاب تمرینات ورزشی مجهز شدهاند.
سیستمهای نظارتی دیگر سیستمهای ساده قدیم نیستند که به وسیله دوربینها روی محیط اطراف خود نظارت داشته باشند. سیستمهای پیشرفته کنونی از یادگیری ماشینی برای وظایف مختلفی شامل تشخیص فعالیتهای مشکوک و ردیابی افراد از طریق تشخیص چهره استفاده میکنند.
امروزه از یادگیری ماشینی در بخشهای مختلفی استفاده میشود، اما چه آیندهای در انتظار این فناوری است؟ در حقیقت هوش مصنوعی تازه در اول راه قرار دارد و میتواند در آینده انقلابی به پا کند.
الگوریتمهای یادگیری ماشینی و یادگیری عمیق فضای نامحدودی برای رشد دارند و بدون شک در دهههای آینده کاربردهای بیشتری برای آنها ایجاد میشود که مصرفکنندگان و همچنین مشتریان سازمانی از آنها بهرهمند خواهند شد.

یادگیری ماشینی در آینده نقش زیادی در زندگی ما خواهد داشت
در حال حاضر بیش از ۸۰ درصد پیشگامان بازار برای بهبود شخصیسازی سرویسهای خود از یادگیری ماشینی استفاده میکنند. بنابراین میتوانیم انتظار داشته باشیم در آینده از ML برای تبلیغات هدفمند و سرویسهای شخصیسازی شده زیادی استفاده شود.
به نظر میرسد پیشرفت بزرگ بعدی در این حوزه، یادگیری ماشینی کوانتومی خواهد بود. محققان از دانشگاهها و کمپانیهای مختلف مانند MIT، ناسا و IBM در حال انجام آزمایشها برای وارد کردن محاسبات کوانتومی به یادگیری ماشینی هستند تا بتوانند برخی مشکلات را در مدت زمان کوتاهی حل کنند.
اخیرا کمپانیهای مایکروسافت و گوگل برنامههای خود برای ورود به حوزه یادگیری ماشینی را اعلام کردهاند. با توجه به این موارد، آینده سیستمهای ML بسیار روشن است و شاهد استفاده از آنها در بخش بیشتر و گستردهتری از زندگی خود خواهیم بود.






پاسخ ها