
پروژهی مشترک مایکروسافت و اینتل با هدف شناسایی سریعتر بدافزارها کلید خورد. این پروژه با نام STAMINA توسعه مییابد.
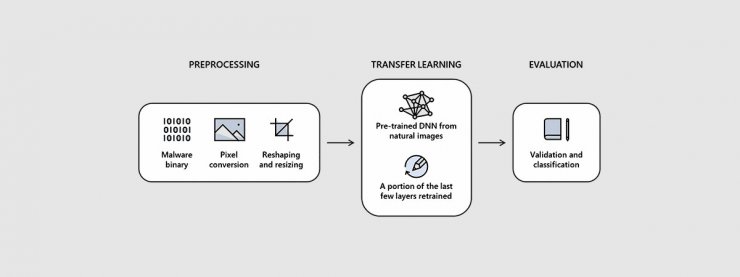
مایکروسافت و اینتل اخیرا در پروژهی تحقیقات امنیتی با یکدیگر همکاری کردهاند که راهکارهای جدید را برای شناسایی و دستهبندی بدافزارها مورد بررسی قرار میدهد. پروژهی مشترک که بهنام STAMINA، مخفف عبارت STAtic Malware-as-Image Network Analysis است، براساس روش تبدیل بدافزار به عکس کار میکند. دستاورد پروژه، ابزاری خواهد بود که نمونههای بدافزار را به تصاویر سیاه و سفید تبدیل کرده و سپس آن را با هدف پیدا کردن الگوهای ساختاری و بافتی مخصوص نمونههای بدافزار، اسکن میکند.
تیم تحقیقاتی متشکل از اینتل و مایکروسافت میگوید فرایند سادهای برای تبدیل کردن نمونهها به عکس و اسکن کردن آنها دارد. در مرحلهی اول، یک فایل بهصورت ورودی به ابزار ارائه شده و سپس فرم باینری آن به جریانی از دادههای پیکسلی خام تبدیل میشود. محققان سپس از جریان یکبعدی دادهی پیکسلی استفاده کرده و آن را به عکس دوبعدی تبدیل میکنند تا الگوریتمهای تحلیل تصاویر مرسوم، توانایی تحلیل آن را داشته باشند.
عرض تصاویری که از دادههای باینری ساخته میشوند، طبق یک جدول و براساس ابعاد فایل ورودی مشخص میشود. طول عکس، مقدار ثابتی ندارد و بهصورت پویا و حاصل تقسیم جریان پیکسل خام بر مقدار عرض تصویر، انتخاب میشود. پس از ساختن یک تصویر دوبعدی با ظاهر عادی از جریان پیکسلها، محققان آن را به ابعاد کوچکتر مقیاسدهی کردند.
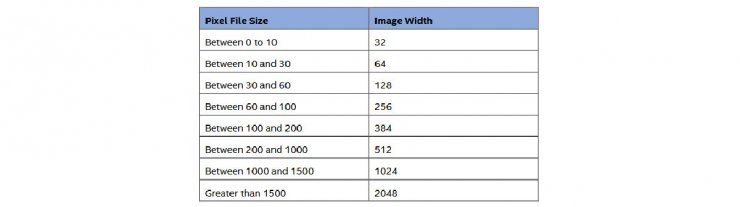
تیم تحقیقاتی اینتل و مایکروسافت میگوید که کاهش ابعاد تصویر خام، تأثیر منفی روی نتایج دستهبندی نهایی ندارد. درواقع کاهش ابعاد به این دلیل انجام شد که سیستمهای پردازش تصویر، نیاز به بررسی و تحلیل میلیاردها پیکسل را نداشته باشند. درنهایت این تصمیم، فشار را روی منابع پردازشی کاهش داده و سرعت کار آنها را افزایش میدهد.
محققان پس از کاهش ابعاد تصویر، آنها را وارد یک شبکهی عصبی عمیق آموزشدیده (DNN) میکنند تا تصاویر را اسکن کند. درواقع، نمای دوبعدی از بدافزار، اسکن شده و سپس در گروههای بیخطر یا آلوده، دستهبندی میشود. مایکروسافت میگوید برای توسعهی پایههای آموزشی پروژه، بیش از ۲/۲ میلیون نمونه از هش فایل PE را ارائه کرده است (Prtable Executable). از میان فایلهای تأمینشده، ۶۰ درصد برای آموزش اولیهی شبکهی عصبی، ۲۰ درصد برای تأیید و ارزیابی عملکرد آن و ۲۰ درصد دیگر برای آزمایشهای نهایی واقعی بهکار گرفته شدند.
گروه تحقیقاتی ادعا میکند STAMINA در آزمایشهای انجامشده به دقت ۹۹/۰۷ درصد در شناسایی بدافزارها رسید و نرخ اعلام آلودگی اشتباه آن نیز ۲/۵۸ درصد بود. گروه دانشمندان مایکروسافت که به نمایندگی از زیرمجموعهی Microsoft Threat Protection Intelligence Team در تحقیقات حاضر بودند اعتقاد دارند نتایج بهدستآمده، امیدواری را دربارهی اثربخشی استفاده از شبکهی عمیق در شناسایی بدافزارهای افزایش میدهد.
تحقیقات اخیر بخشی از فعالیتهای مایکروسافت در حوزهی شناسایی بدافزار با روشهای یادگیری ماشین بود. همانطور که گفته شد STAMINA از یادگیری عمیق برای شناسایی بدافزارهای بهره میبرد. یادگیری عمیق زیرمجموعهای پرکاربرد از یادگیری ماشین محسوب میشود که خود زیرمجموعهی هوش مصنوعی است. شبکههای کامپیوتری هوشمند که توانایی یادگیری براساس دادههای ورودی بدون ساختار و فرمتدهی خاص را دارند، شبکههای عصبی یادگیری عمیق را تشکیل میدهند. در تحقیق اخیر، دادههای ورودی همان دادههای باینری تصادفی از بدافزارها هستند.
مایکروسافت میگوید باوجود دقت بالای STAMINA در تشخیص بدافزارها در ابعاد کوچک، عملکرد آن در اسکن فایلهای بزرگ آنچنان موفق نبود. طبق اطلاعاتی که در یک پست وبلاگی توسط ردموندیها منتشر شد، محدودیت تبدیل میلیاردها پیکسل به تصاویر JPG و سپس تغییر ابعاد آنها، منجر به کاهش دقت سیستم در فایلهای بزرگ میشود. بههرحال میتوان از دستاورد این پروژه برای فایلهای کوچک بهره برد و روی دقت بالای آن حساب کرد.
تانمای گاناچاریا، مدیر بخش تحقیقات امنیتی Microsoft Threat Protection چندی پیش گفته بود که شرکتش اکنون برای شناسایی تهدیدهای روزافزون امنیت سایبری بیش از همیشه از یادگیری ماشین استفاده میکند. به گفتهی او، یادگیری ماشین در سیستمهای امنیتی، ساختاری متفاوت با فناوری مورد استفاده در سیستمهای مخصوص مشتری یا سرورهای مایکروسافت دارد. گاناچاریا میگوید مایکروسافت اکنون از موتورهای مدل یادگیری ماشین در سمت کاربر، موتورهای مدل یادگیری ماشین در سمت کلاد و ماژولهای یادگیری ماشین برای شناسایی توالی رفتارها یا شناسایی محتوای فایل استفاده میکند.
باتوجه به نتایج بهدست آمده، میتوان پیشبینی کرد که STAMINA بهزودی به یکی از ماژولهای یادگیری ماشین تبدیل شود که در مایکروسافت برای شناسایی بدافزارها کاربرد خواهد داشت. بههرحال ردموندیها اکنون بهخاطر دادههای عظیمی که از ویندوز دیفندر دریافت میکنند، بیش از همهی شرکتها توانایی توسعه و افزایش بهرهوری فناوری را دارند. گاناچاریا دربارهی این برتری میگوید: «هر شرکت یا گروه تحقیقاتی توانایی ساختن مدل را دارد، اما دادههای برچسبگذاریشده در حجم و کیفیت قابلتوجه، کمک شایانی به آموزش مدلهای یادگیری ماشین میکنند و بهنوعی اثرگذاری آنها را نشان میدهند. ما در مایکروسافت، مزیت کیفیت و کمیت قابلتوجه داده را داریم».





پاسخ ها