
شتابدهندههای هوش مصنوعی از ابزارهای مهم پردازشی این فناوری محسوب میشود و Groq یکی از استارتاپهای فعال در این زمینه است.
استارتاپ Groq یکی از شرکتهای متعددی است که در حوزهی ساخت کارتهای شتابدهندهی هوش مصنوعی فعالیت میکند. آنها دومین بازیگر بازار محسوب میشوند و موفق به تولید اولین محصول با قابلیت انجام یک کوادریلیون عملیات در ثانیه شدهاند. چنین عملکردی چهار برابر قویتر از قدرتمندترین کارت شتابدهندهی انویدیا است.
پردازندههای شتابدهندهی هوش مصنوعی که بهنام پردازندهی استریم تنسور یا TSP شناخته میشوند، رویکردی تقریبا متفاوت با پردازندههای عادی دارند. محصول گراک، برای هر هستهی پردازشی به ۳۰۰ وات نیرو نیاز دارد. البته این پردازنده مجهز به تنها یک هستهی پردازشی است که گراک، آن را از یک نقطهی ضعف، به بزرگترین مزیت رقابتی خود تبدیل کرد. بههرحال برای درک ساختار TSP، باید هرچه از پردازندههای گرافیکی یا پردازندههای هوش مصنوعی میدانیم، کنار بگذاریم. TSP یک قطعهی سیلیکونی بزرگ محسوب میشود که تنها به واحدهای پردازشی ماتریسی و برداری مجهز خواهد بود. هیچگونه کنترلر یا ساختار Backend در این پردازندهها وجود ندارد و کامپایلر، کنترل کامل را در دست میگیرد.
واحد پردازی TSP از ۲۰ واحد موسوم به Superlane تشکیل میشود که از چپ به راست، اینگونه هستند: واحد ماتریسی 320MAC، واحد سوئیچ، واحد حافظهی ۵/۵ مگابایتی، واحد برداری 16ALU، واحد حافظهی ۵/۵ مگابایتی، واحد سوئیچ، واحد ماتریسی 320MAC. با نگاهی به الگوی مذکور، متوجه آینهای بودن جانمایی واحدها میشویم که در اطراف واحد برداری طراحی شدهاند. درنتیجه، سوپرلینها به دو نیمکره تقسیم میشوند که هرکدام توانایی عملکرد مستقل دارند.
جریان دستورالعملها که در TSP تنها یک عدد است، به تمامی اجزاء تشکیلدهندهی سوپرلین صفر وارد میشود. ۷ دستورالعمل برای واحدهای ماتریسی، ۱۴ دستور برای واحدهای سوئیچ، ۴۴ دستور برای واحدهای حافظ و ۱۶ دستور برای واحد برداری ارسال میشود. واحدها هر چرخهی کلاک، عملیات خود را انجام میدهند و تکههای داده را به بخش بعدی در سوپرلین منتقل میکنند. هر قطعه، توانایی ارسال و دریافت ۵۱۲ مگابایت داده از همسایهی خود دارد.
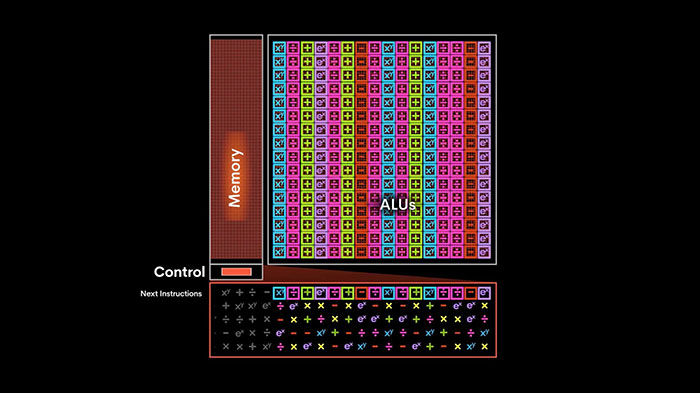
وقتی عملیات سوپرلین تمام شود، همهی نتایج به سوپرلین بعدی بعدی منتقل و دستورالمل یا رویکرد بعدی از کنترلکنندهی دستورالعمل یا سوپرلین بالایی دریافت میشود. درواقع دستورالعملها همیشه بهصورت عمودی بین سوپرلینها جابهجا میشوند و داده تنها تنها بهصورت افقی در داخل سوپرلین حرکت میکند.
روند فعالیت TSP، آن را به پردازندهای عالی برای آموزش شبکههای عصبی و استنباط داده تبدیل میکند. همین روندها، هرگونه کارایی دیگر را از TSP سلب میکنند. بنچمارکهای اولیه از شتابدهندهی گراک در ResNet-50 نشان میدهند که این واحد پردازشی توانایی انجام ۲۰،۴۰۰ استنباط در ثانیه (I/S) را دارد و تأثیر استنباط آن نیز ۰/۰۵ میلیثانیه گزارش میشود.
پردازندهی انویدیا تسلا V100 در ابعاد دستهای ۱۲۸، توانایی انجام ۷،۹۰۷ استنباط در ثانیه دارد و درصورت استفاده از یک دسته، قدرت ۱،۱۵۶ استنباط در ثانیه خواهد داشت. البته تعداد دستههای پردازشی هیچگاه به این اندازه کوچک نخواهد بود، اما بههرحال تنوع TSP را نشان میدهد. تأخیر در شتابدهندهی انویدیا در حالتهای بالا، ۱۶ و ۰/۸۷ میلیثانیه گزارش میشود. نتایج بالا نشان میدهند که محصول گراک، با فاصلهی قابلتوجهی رقیب شبیه به خود از انویدیا را شکست میدهد.
| Groq TSP | Nvidia Tesla V100 | Nvidia Tesla T4 | |
|---|---|---|---|
| تعداد هسته | یک | ۵،۱۲۰ | ۲،۵۶۰ |
| حداکثر فرکانس | ۱،۲۵۰ مگاهرتز | ۱،۵۳۰ مگاهرتز | ۱،۵۹۰ مگاهرتز |
| FP16 TFLOPS | ۲۰۵ | ۱۲۵ | ۶۵ |
| INT8 TOPS | ۱،۰۰۰ | ۲۵۰ | ۱۳۰ |
| کش تراشه (L1) | ۲۲۰ مگابایت | ۱۰ مگابایت | ۲/۶ مگابایت |
| حافظهی اضافه | ندارد | ۳۲ گیگابایت HBM2 | ۱۶ گیگابایت GDDR6 |
| برق مصرفی | ۳۰۰ وات | ۳۰۰ وات | ۷۰ وات |
| فرایند تولید | ۱۴ نانومتری | ۱۲ نانومتری | ۱۲ نانومتری |
| ابعاد قالب | ۷۲۵ میلیمتر مربع | ۸۱۵ میلیمتر مربع | ۵۴۵ میلیمتر مربع |
از مزیتهای TSP میتوان به تجهیز به حافظهی کش L1 اشاره کرد. البته کارتهای مذکور، تنها همین قابلیت اضافه را دارند و اگر یک شبکهی عصبی، توسعه پیدا کرده و دادههای ورودی بیشتری دریافت کند، قطعا با مشکل روبهرو میشوند. درمقابل، کارتهای انویدیا مجهز به چندین گیگابایت حافظه هستند که افزایش ابعاد و ورودیهای شبکهی عصبی را سازماندهی میکند.
در مجموع میتوان TSP را یک ابزار شتابدهی کاملا مناسب در حوزهی هوش مصنوعی دانست. محصول گراک در بسیاری از وظایف، انویدیا Tesal V100 را شکست میدهد، اما اگر فرایند کاری هوش مصنوعی متنوع باشد، قابلیتهای TSP محدود خواهد شد. TSP قطعا در حوزههایی همچون خودروهای خودران، کاربرد دارد. در این حوزهها، حجم دادهی ورودی محدود و قابل پیشبینی است و شبکهی عصبی بهخوبی قابلیت هماهنگی دارد. در چنین کاربردهایی، تأخیر پایینتر ۳۲۰ برابری TSP نسبت به انویدیا، منجر به پاسخگویی سریعتر خودروی هوشمند می شود. شتابدهندهی مذکور اکنون ازطریق شبکهی ابری Nimbix در اختیار مشتریان خاص قرار دارد.





پاسخ ها