آگنر فاگ، پژوهشگر فعال در حوزه پردازندهها نتایج بررسی دقیق خود از معماری Zen 2 شرکت AMD را منتشر کرده و موفق به کشف قابلیت جدیدی شده که AMD آن را درجایی بازگو نکرده است. احتمالا علت این امر، برخی نارساییهای این قابلیت باشد.
آگنر فاگ در زمینهی ویژگیهای زیرساختی (Low-level) و معماری نرمافزاری پردزاندهها تحقیق میکند. آگنر همچنان درحال انتشار بهروزرسانیهای دورهای خود دربارهی دفترچهی راهنمای پردازندهها است که در آن معماریهای مختلف AMD و اینتل را مقایسه میکند. یافتههای او از یک ویژگی در تراشههای Zen 2 تولیدشده توسط AMD پرده برداشتهاند که پیشاز این درجایی بازگو نشده بودند.
آگنر برای انجام آزمایشهای خود، فهرست بلندبالایی از بنچمارکهای میکرو عملیاتی تدارک دیده است تا تمام جزئیات عملکرد تراشهها را بیرون بکشد. نمودارهای رسمی دورهی دستورالعمل که توسط اینتل و AMD منتشر میشوند، دقت کافی را ندارند و آگنر در گذشته، باگهای فاشنشدهای از دل پردازندههای x86 پیدا کرد که شامل مشکلاتی در انجام عملیات مربوط به کد AVX2 در معماری Piledriver و مشکلاتی در پایپلاین اصلی هستهی واحد ممیز شناور (FPU) میشده است.
بیشتر بخشهای جزئیات سطح پایین یا بهعبارتی زیرساختی، برای افرادی که چگونگی تکامل معماری Zen به Zen 2 را مطالعه کردند، آشنا است. حداکثر میزان اندازهگیریشدهی توان عملیاتی، گرفتن دستور از حافظه (Fetch) بر ترد، همچنان ۱۶ بایت است. هرچند، ناگفته نماند که پردازنده ازنظر تئوری میتواند تا حجم ۳۲ بایت دستور همراستا بر هر سیکل کلاک را (fetch/clock cycle) دریافت کند. پردازنده روی نرخ دیکود باثبات ۴ دستورالعمل بر سیکل کلاک (IPC) محدود شده است؛ اما این میزان میتواند تا عدد ۶ دستورالعمل در هر سیکل افزایش یابد، فقط بهشرطی که نیمی از دستورالعملها هرکدامشان دو میکرو عملیات تولید کنند. دراینصورت با دو دستورالعمل تک و دو دستورالعمل دوتایی روبهرو خواهیم بود. البته، درنظر داشته باشید که این فرایند در اکثر اوقات اتفاق نمیافتد.
از نظر تئوری، اندازهی حافظهی کش میکرو عملیاتها ۴٬۰۹۶ µops عنوان شده؛ اما میزان مؤثر میکرو عملیاتها در یک رشته یا ترد (thread) بهتنهایی، براساس محاسبات آگنر، ۲٬۵۰۰ µops اندازهگیری شده است؛ بنابراین این رقم در دو ترد، قاعدتا دوبرابر مؤثر خواهد شد. حلقههای دستوری داخل حافظهی کش نیز میتوانند با ۵ IPC (دستورالعمل بر سیکل) اجرا شوند؛ البته فراموش نکنید که تحت شرایط خاص گفتهشده، ممکن است میزان IPC تا ۶ عدد نیز برسد.
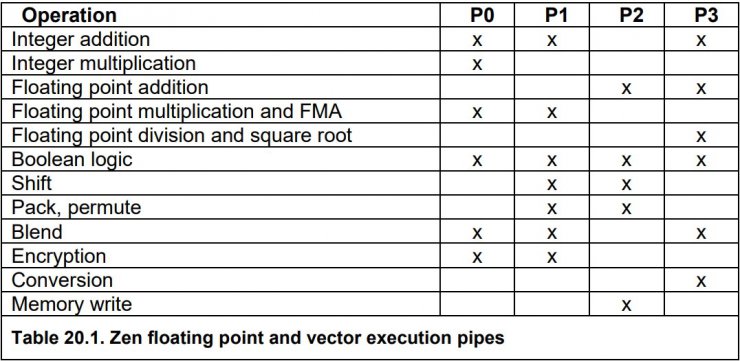
آزمایشهای سطح پایین همچنین، برخی برتریهای معماری Zen 2 نسبت به Zen را تأیید کردند. در معماری Zen تراشه میتواند همزمان دو خواندن (read) داشته باشد یا توان خود را بین یک خواندن و یک نوشتن در همان سیکل تقسیم کند؛ درحالیکه در معماری Zen 2 تراشه قادر است دو خواندن و یک نوشتن را اجرا کند. برای مثال، جدول زیر نشان میدهد که دستورالعمل ممیز شناور چگونه براساس پایپهای اجرایی مختلف باتوجهبه وظیفهی مدنظر (task) بهکار گرفته میشوند.
یکی دیگر از تفاوتهایی که AMD در Zen 2 آن را معرفی کرده، توانایی میرورکردن (mirror) حافظهی عملوندها (operand) است. این ویژگی در برخی عملیاتها میتواند تعداد سیکل کلاکها را برای اجرای عملیات بهطرز چشمگیری، برای مثال از ۱۵ به ۲ کاهش دهد. برای اجرای موفقیتآمیز عمل میرورکردن چند پیششرط لازم است که برای مثال میتوان بهچند مورد از آنها اشاره کرد. مورد اول این است که دستورالعملها باید از رجیسترهایی همهمنظوره (عمومی) استفاده کنند، حافظهی عملوندها باید آدرس یکسانی داشته باشند، اندازهی عملوندها باید ۳۲ یا ۶۴ بیت باشد: البته درنظر داشته باشید که بعداز نوشتن یک بستهی ۶۴ بیتی میتوان یک بستهی ۳۲ بیتی را تحت فرایند خواندن در همان آدرس قرار داد. البته ناگفته نماند که فرایند خواندن و نوشتن بهصورت معکوس آنچه گفته شد بههیچوجه امکانپذیر نیست.
ازآنجایی که این ویژگی درجایی ثبت نشده است، مشخص نیست که آیا شخصی توانسته است آن را بهصورت عملی در ارسال کد بهکار گیرد یا خیر. آگنر خاطرنشان کرد که این قابلیت بیشتر در حالت ۳۲ بیتی بهرهوری کافی خواهد داشت. وی در ادامه افزود، اگر پردازنده با استنباطهای نادرست خاصی مواجه شود، افت عملکرد خواهد داشت. این نارسایی را شاید بتوان علت عدم ثبت و معرفی این قابلیت دانست. AMD احتمالا قصد داشته است از تشویق توسعهدهندگان برای استفاده از این قابلیت که احتمال ایجاد مشکل در عملکرد را بههمراه دارد، جلوگیری کند.
فاگ درنهایت نظر کلی خود را دربارهی Zen چنین بیان کرده است:
درنهایت میتوان نتیجه گرفت که ریزمعماری Zen دارای طراحی کارآمدی است و حافظهی کش و حافظهی کش میکرو عملیات زیادی ارائه میکند و واحدهای اجرایی بزرگی را با توان عملیاتی بسیار بالا و تأخیر پایین دربر میگیرد.







پاسخ ها